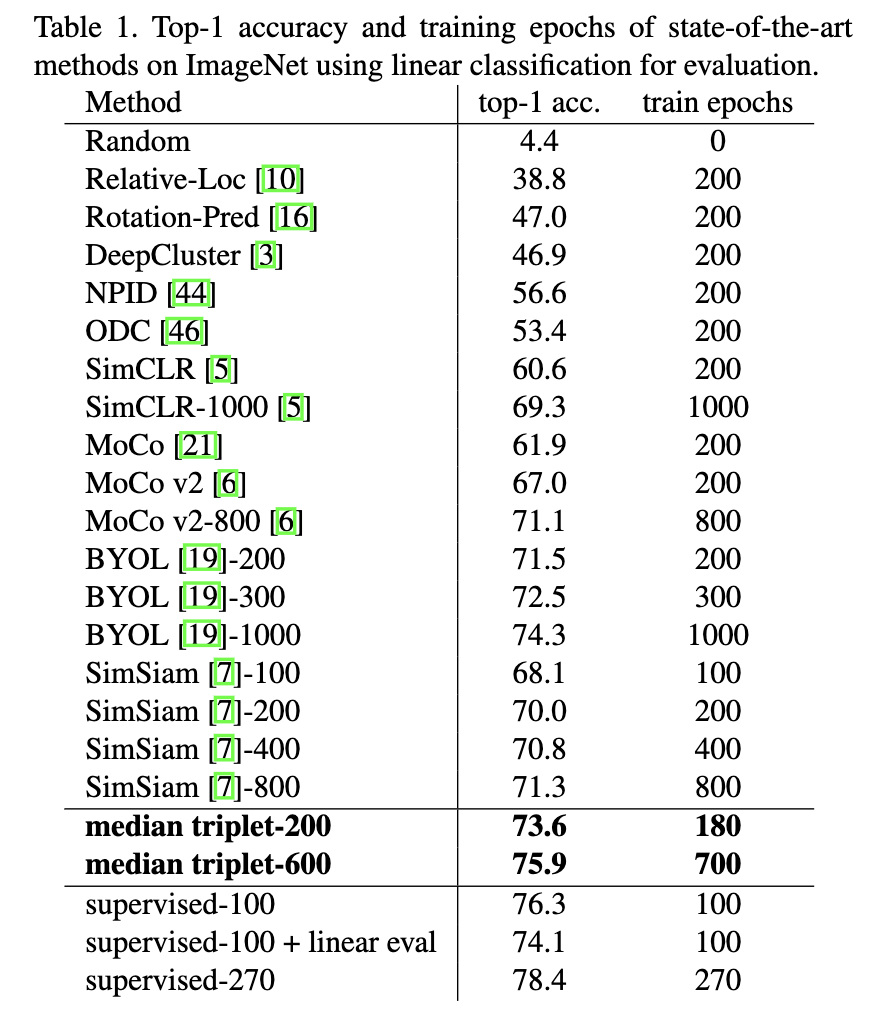
自监督学习效率比全监督低很多(e.g.,100 epochs v.s. 1000 epochs),论文把这一现象的原因归结为欠聚类(under clustering)或过聚类(over clustering),并提出了一个median triplet loss来提高训练的效率,同时提升性能。
Introduction
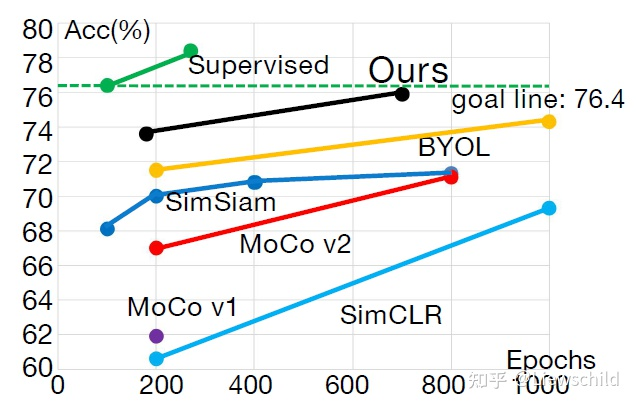
作者首先分析了之前自监督方法与有监督方法之间的效率对比,如下图所示,可以看到有一条绿线,叫goal line,那是全监督训练100 epochs的性能,对比此前性能最优的BYOL,训练1000 epochs,性能也没有达到76.4,这就是作者所说的,(基于对比学习的)自监督学习效率低的问题。为什么效率低?作者把原因归结为欠聚类(under clustering)或过聚类(over clustering)。
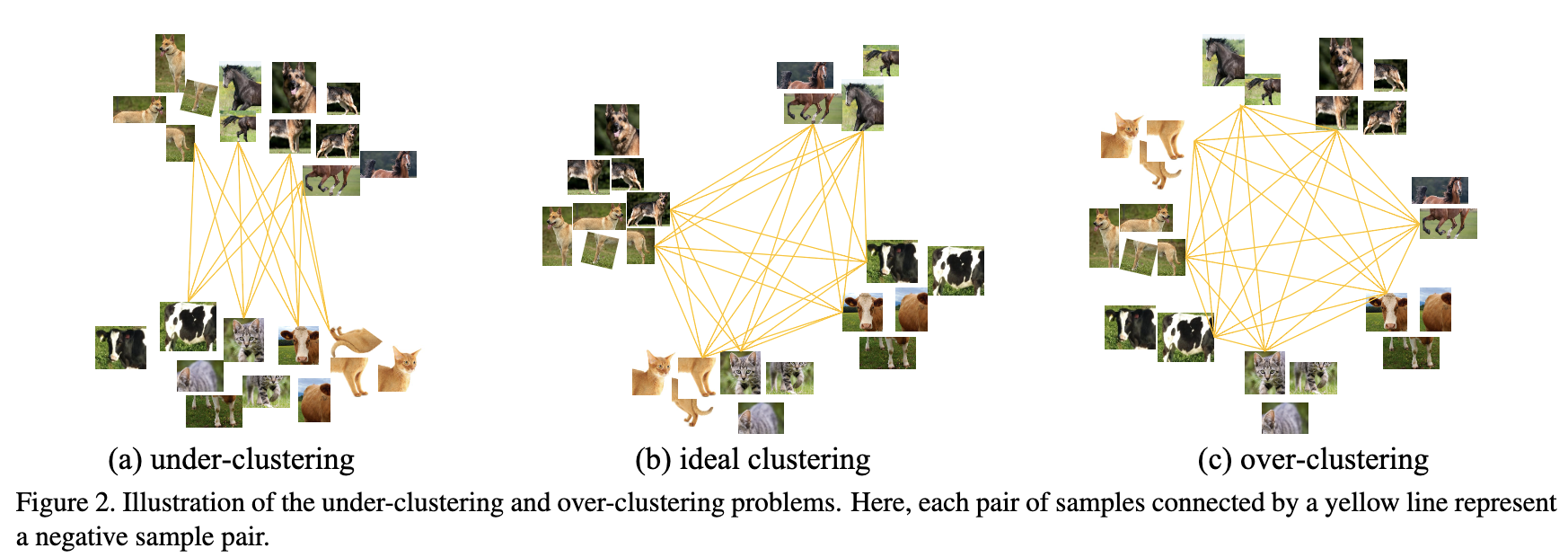
Under-clustering and Over-clustering Problems
所谓欠聚类,就是把不同的类别划分为同一类别了,如下图中的a所示,把猫和奶牛划分为同一类了,出现这种情况的原因是正负样本不足(应该是针对BYOL和Simsiam这种不使用负样本的方法);所谓过聚类,就把本该属于同一类的,继续划分为多个类了,如下图中的c所示,出现这种情况的原因是,(对比学习中的)大量负样本中,会有和query属于同一类的样本,这些样本不应该作为负样本。过聚类会导致错误的loss,错误的梯度,确实会降低训练的效率。
Median Triplet Loss
作者提出了median triplet loss来解决欠聚类和过聚类的问题。首先回顾triplet loss的公式:
$$
\mathcal{L o s s}=\max \left(d\left(x, x^{+}\right)-d\left(x, x_{\text {hardest }}^{-}\right), \mathcal{C}\right)
$$
一般会选择最难的样本作为负样本。triplet loss解决了欠聚类的问题(正负样本都有),但可能带来过聚类的风险,因为最难的样本可能是正样本(如两只不同图片中的狗狗)。这里的难是通过余弦相似度来衡量的,余弦相似度越大,越难。
为了解决这个问题,作者提出了median triplet loss,不选最难的负样本,而是选择第k难的那个,对应median的话,就是batch里中间位置的负样本。
$$
\mathcal{L o s s}=\max \left(\gamma d\left(x, x^{+}\right)-d\left(x, x_{\text {rank-k }}^{-}\right), \mathcal{C}\right)
$$
Main Results
性能下图所示,跟之前的的BYOL、Simsiam、MoCo、SImCLR相比,median triplet确实效率高很多,而且性能还高,median triplet训练200 epcohs性能就基本超过其他各种方法训练800或1000 epochs的性能,除了训1000 epochs的BYOL;median triplet训练600epochs,吊打其他所有方法训练800或1000 epochs的性能。简而言之,又快又好。